Bayes formel (även kallad Bays sats) beskrier matematiskt hur vi bör uppdatera vår världsbild i ljuset av ny information. Den är därför ett viktigt redskap när man försöker dra slutsatser av naturvetenskapliga experiment, såväl i vardagen som i vården och rättsväsendet.
Formeln
Låt H vara en hypotes, dvs. ett påstående som vi bedömer är sant med någon viss sannolikhet, och låt E vara en observation som vi har gjort, som påverkar sannolikheten för H.
Bayes sats säger då att vi borde uppdatera sannolikheten för H enligt formeln
\[P(H|E)={\color{black}{\frac{P(E|H)\color{black}{\cdot P(H)}}{P(E|H)\cdot P(H)+P(E|\lnot H)\cdot P(\lnot H)}}}\,,\]
där
- \(\small P(H)\) är den initiala sannolikheten för H, innan vi gjorde observationen E
- \(\small P(\lnot H)=1-P(H)\) är den initiala sannolikheten för att H är falsk
- \(\small P(H|E)\) är den uppdaterade sannolikheten för H, efter observationen E
- \(\small P(E|H)\) är sannolikheten att vi skulle observera E, om H vore sann
- \(\small P(E|\lnot H)\) är sannolikheten att vi skulle observera E, om H vore falsk.
Tolkning
Huvudbudskapet i Bayes formel är att det finns tre olika parametrar att ta hänsyn till när vi uppdaterar sannolikheter i ljuset av ny information:
- Hur sannolik vi bedömde att hypotesen H var innan vi gjorde observationen E. Detta motsvaras av sannolikheten \(\small P(H)\).
- Hur pass förväntat det är att göra observationen E om hypotesen H vore sann. Detta motsvaras av \(\small P(E|H)\).
- Hur pass sannolika eventuella alternativa förklaringar till observationen E är. Detta motsvaras av \(\small P(E|\lnot H)\).
Ett vanligt fel vi människor begår när vi intuitivt bedömer sannolikheter, är att vi glömmer bort punkt 1 och 3, och i stället antar att \(\small P(H|E)\approx P(E|H)\). Som vi kommer att se i exempeluppgifterna nedan är detta oftast helt fel!
Första gången man ser en formel är det en god idé att göra en snabb rimlighetsanalys. Dels för att upptäcka eventuella fel, och dels för att det är ett bra sätt att ”lära känna” formeln och bygga upp en känsla för hur den fungerar.
Gör en snabb kontroll av rimligheten i Bayes formel! Du kan t.ex. kolla om \(\small P(H|E)\) får en rimlig storlek (värdet borde ligga mellan 0 och 1). Fundera också på hur \(\small P(H|E)\) intuitivt borde bero på parametrarna \(\small P(E|H)\) och \(\small P(E|\lnot H)\), och undersök om detta stämmer med formeln.
Bayes formel säger att
\[\small P(H|E)=\frac{P(E|H)\cdot P(H)}{P(E|H)\cdot P(H)+P(E|\lnot H)\cdot P(\lnot H)}\,.\]
Intuition: Eftersom det är en sannolikhet, borde \(\small P(H|E)\) anta värden mellan 0 och 1.
Analys: Detta stämmer med att formeln säger att \(\small P(H|E)\) är en kvot, där nämnaren är täljaren plus en extra term \(\small P(E|\lnot H)P(\lnot H)\). Det betyder att nämnaren alltid är minst lika stor som täljaren, vilket i sin tur innebär att kvoten aldrig kan bli större än 1. Eftersom varken täljare och nämnare kan vara negativa, så måste kvoten vara större än eller lika med 0.
Intuition: Om \(\small P(E|H)\) ökar så borde \(\small P(H|E)\) öka; ju mer väntad observationen E är om H vore sann, desto bättre belägg för H borde den ge.
Analys: Detta stämmer med formeln! Om \(\small P(E|H)\) ökar i formeln (och \(\small P(H)>0\), så ökar termen \(\small P(E|H)P(H)\) i nämnaren. Det gör att betydelsen av den extra termen \(\small P(E|\lnot H)P(\lnot H)\) minskar, vilket får kvoten att växa och blir mer lik \[\small \frac{P(E|H)P(H)}{P(E|H)P(H)}=1\,,\] precis som väntat.
Intuition: Om \(\small P(E|\lnot H)\) ökar så borde \(\small P(H|E)\) minska; ju troligare alternativa förklaringar det finns, desto svagare belägg ger observationen, och desto mindre borde \(\small P(H|E)\) bli.
Analys: Detta stämmer också! Formeln säger att om \(\small P(E|\lnot H)\) ökar (och \(\small P(\lnot H)>0\) , så blir den extra termen \(\small P(E|\lnot H)P(\lnot H)\) i nämnaren större, vilket gör kvoten mindre.
Exempel och grafisk tolkning
Ett av de mest klassiska exemplen när det kommer till Bayes formel är hämtat från vården:
En screening är en medicinsk undersökning där man letar efter en sjukdom hos en stor grupp människor utan att de har några symptom på sjukdomen. Det typiska exemplet är mammografi, där man letar efter bröstcancer. Man screenar även i varierande grad för exempelvis prostacancer, könssjukdomar samt vissa ämnesomsättningssjukdomar hos barn.
Screeningtester är sällan helt perfekta. Dels finns det en risk för att patienter som är sjuka friskförklaras, och dels finns det en risk för att patienter som är friska får besked om att de är sjuka.
Anta att Adam screenas för en viss sjukdom X, som i snitt 10 % av befolkningen beräknas vara drabbad av (det är med andra ord en ganska vanlig sjukdom), så att
\[P(\text{sjuk})=0{,}10\,.\]
Om testet är positivt indikerar det att Adam har sjukdomen. Om testet är negativt indikerar det att Adam är frisk. Läkaren berättar att 90 % av alla sjuka individer testar positivt, dvs. att
\[P(\text{positivt}\,|\,\text{sjuk})=0{,}90\,,\]
och att risken att frisk person testar positivt är 10 %, dvs. att
\[P(\text{positivt}\,|\,\text{frisk})=0{,}10\,.\]
Anta att Adam testar positivt. Han blir så klart orolig. Instinktivt skulle många tolka detta som att han med stor sannolikhet är sjuk. Men vad säger Bayes formel?
Vi är intresserade av den uppdaterade sannolikheten för att Adam är sjuk, efter observationen att han har testat positivt för sjukdomen, dvs. \(\small P(\text{sjuk}\,|\,\text{positivt})\). Enligt Bayes formel är
\[P(\text{sjuk}\,|\,\text{positivt})=\small\frac{P(\text{positivt}\,|\,\text{sjuk})P(\text{sjuk})}{P(\text{positivt}\,|\,\text{sjuk})P(\text{sjuk})+P(\text{positivt}\,|\,\text{frisk})P(\text{frisk})}.\]
Med insatta värden får vi
\[P(\text{sjuk}\,|\,\text{positivt})={\small\frac{0{,}9\cdot 0{,}1}{0{,}9\cdot 0{,}1+0{,}1\cdot (1-0{,}1)}}\approx 0{,}5\,.\]
dvs. sannolikheten att Adam är sjuk är inte mer än 50 %. Detta strider mot mångas intuition. Under fliken ”Grafisk tolkning” ger vi därför en visuell förklaring.
Låt oss rita en bild! Föreställ dig att vi testar 100 slumpmässigt utvalda personer. Av dessa förväntar vi oss att 10 % har sjukdomen (rödmarkerade), medan resten inte har den.

Vi förväntar oss sedan att 90 % av de med sjukdomen och 10 % av de utan sjukdomen testar sedan positivt (markeras med röd bakgrund). Vi får följande figur:

Eftersom vi vet att Adam testade positivt, kan vi tänka oss att han är en av personerna med röd bakgrund, dvs. någon av dessa:

Med hjälp av ett klassiskt ”delen genom det hela”-argument kommer vi fram till att

eller, uttryckt i sannolikheter:

vilket är precis vad Bayes formel säger!
Anledningen till \(\small P(\text{sjuk}\,|\,\text{positivt})\) blir så liten är att sjukdomen är så pass ovanlig, så att även om risken för en enskild frisk person att få ett falskt positivt resultat är liten, så kommer det totalt att vara ganska många friska personer som testar positivt.
Att på detta vis glömma att ta hänsyn till den initiala sannolikheten är ett vanligt misstag, och kallas för the base rate fallacy på engelska.
Den visuella ”delen genom det hela”-tolkningen som vi gjorde i Exempel 1 ovan kan också användas som en generell motivering till varför Bayes formel gäller:

Varje punkt motsvarar här ett ”slumpmässigt genererat universum” där vår hypotes H är antingen sann (röd punkt •) eller falsk (svart punkt •), och där vi antingen har (röd bakgrund) eller inte har (vit bakgrund) gjort observationen E.
Om vi vet att vi har gjort observationen E så så betyder det att verkligheten motsvarar en punkt med röd bakgrund, och Bayes formel följer då av ”delen genom det hela”:
![]()
På den här länken finns en interaktiv GeoGebra-applet, där du själv kan experimentera med figurer som den ovan. Använd gärna appleten samtidigt som du löser övningsuppgifterna nedan!
Övningsuppgifter
Här följer ytterligare ett par exempel på användningsområden för Bayes formel. Försök gärna svara på frågorna själv innan du tittar på våra lösningar.
a) Vad händer med svaret i föregående exempel, om Adam har visat symptom på sjukdomen X, så att läkaren misstänker att Adam har sjukdomen med sannolikhet 40 % innan testet görs? Räkna med
\[\small P(\text{sjuk})=0{,}4\quad P(\text{positivt}\,|\,\text{sjuk})=0{,}9\quad P(\text{positivt}\,|\,\text{frisk})=0{,}1\,.\]
b) Vad händer om läkaren i stället bedömer att Adam av någon anledning (t.ex. låg ålder) antagligen inte har sjukdomen, så att den initiala sannolikheten att Adam är sjuk bara är 1%? Räkna med
\[\small P(\text{sjuk})=0{,}01\quad\:P(\text{positivt}\,|\,\text{frisk})=0{,}9\quad\: P(\text{positivt}\,|\,\text{frisk})=0{,}1\,.\]
c) Blir diagnosen säkrare om testet blir bättre på att identifiera folk som är sjuka? Räkna med
\[\small P(\text{sjuk})=0{,}01\quad\:P(\text{positivt}\,|\,\text{sjuk})=0{,}95\quad\: P(\text{positivt}\,|\,\text{frisk})=0{,}1\,.\]
d) Vad händer om vi har ett helt perfekt test, sådant att precis alla sjuka personer testar positivt och alla friska personer testar negativt? Räkna med
\[\small P(\text{sjuk})=0{,}01\quad\:P(\text{positivt}\,|\,\text{sjuk})=1\quad\: P(\text{positivt}\,|\,\text{frisk})=1\,.\]
Om sannolikheten att Adam är sjuk bedöms vara 40 % innan testet, så får vi
\[P(\text{sjuk}\,|\,\text{positivt})=\frac{0{,}9\cdot 0{,}4}{0{,}9\cdot 0{,}4+0{,}1\cdot 0{,}6}\approx 85\,\%\,.\]

Om sannolikheten att Adam är sjuk bedöms vara 1 % innan testet, så får vi
\[P(\text{sjuk}\,|\,\text{positivt})=\frac{0{,}9\cdot 0{,}01}{0{,}9\cdot 0{,}4+0{,}1\cdot 0{,}99}\approx 8\,\%\,.\]
Problemet med att screeningtester tenderar att vara ganska intetsägande blir alltså värre ju ovanligare/osannolikare sjukdomen i fråga är.

Om testet upptäcker 95 % (snarare än 90 %) av alla som är sjuka får vi
\[P(\text{sjuk}\,|\,\text{positivt})=\frac{0{,}95\cdot 0{,}01}{0{,}95\cdot 0{,}01+0{,}1\cdot 0{,}99}\approx 9\,\%\,,\]
dvs. det blir ingen märkbar förbättring.
Kommentar: För att få en märkbar förbättring i säkerheten på diagnosen räcker det inte med att P(positivt|sjuk) ökar, utan det som framför allt behövs är att P(positivt|frisk) minskar. Testa gärna detta själv genom att justera sannolikheterna i formeln.
Rita också gärna en egen figur!
Med ett perfekt test får vi
\[P(\text{sjuk}\,|\,\text{positivt})=\frac{1\cdot 0{,}01}{1\cdot 0{,}01+0\cdot 0{,}99}\approx 100,\%\,,\]
dvs. man kan (så klart) lita helt och hållet på positiva resultat!

Anta att Adam testar negativt i ett test där följande värden gäller:
\[\small P(\text{sjuk})=0{,}1\quad\:P(\text{positivt}\,|\,\text{sjuk})=0{,}9\quad\: P(\text{positivt}\,|\,\text{frisk})=0{,}1\,.\]
Hur säker kan han då vara på att han är frisk?
Vi är intresserade av \(\small P(\text{frisk}\,|\,\text{negativt})\). Enligt Bayes formel är
\[\small P(\text{frisk}\,|\,\text{negativt})=\frac{P(\text{negativt}\,|\,\text{frisk})P(\text{frisk})}{P(\text{negativt}\,|\,\text{frisk})P(\text{frisk})+P(\text{negativt}\,|\,\text{sjuk})P(\text{sjuk})}\,.\]
Vi bestämmer de ingående sannolikheterna var för sig:
- \(\small P(\text{sjuk})=0{,}1\) är den initiala sannolikheten för att Adam är sjuk.
- \(\small P(\text{frisk})=1-P(\text{sjuk})=1-0{,}1=0{,}9\) är den initiala sannolikheten för att Adam är frisk.
- \(\small P(\text{negativt}\,|\,\text{frisk})=1-P(\text{positivt}\,|\,\text{frisk})=1-0{,}1=0{,}9\) är sannolikheten för att Adam skulle testa negativt om han vore frisk.
- \(\small P(\text{negativt}\,|\,\text{sjuk})=1-P(\text{positivt}\,|\,\text{sjuk})=1-0{,}9=0{,}1\) är sannolikheten för att Adam skulle testa negativt om han vore sjuk.
Vi får därmed att
\[P(\text{frisk}\,|\,\text{negativt})=\small\frac{0{,}9\cdot 0{,}9}{0{,}9\cdot 0{,}9+0{,}1\cdot 0{,}1}\approx 0{,}99\,,\]
dvs. testet ger ganska gott stöd för att Adam skulle vara frisk.
Visuellt har vi denna situation:

där den blå bakgrunden indikerar individer som testar negativt. Bland dessa är det tydligt att de friska individerna är i majoritet. Mer precist får vi
![]()
Rattfylleri är ett stort trafiksäkerhetsproblem, och enligt Trafikverket är i genomsnitt 1 av 500 bilförare rattfull. Polisen genomför därför ibland slumpmässiga trafiknykterhetskontroller för att upptäcka rattfyllerister. Det första steget är att föraren får blåsa in ett sållningsinstrument som mäter alkoholhalten i utandningsluften. Om resultatet blir negativt får föraren köra vidare. Om resultatet blir positivt blir föraren misstänkt för rattfylleri och får följa med och genomgå ett noggrannare test som säkerställer om alkoholhalten i blodet verkligen överstiger den lagliga gränsen.
Att misstänkas för rattfylleri så klart obehagligt, och redan det första sållningstestet är därför utformat så att risken att en oskyldig person blir misstänkt är mycket liten (i de efterföljande testerna är risken ännu lägre, så risken att i slutändan bli oskyldigt dömd är närmast obefintlig). Samtidigt är det viktigt att så många rattfyllerister som möjligt upptäcks.
Anta att Polisen funderar på att köpa in nya sållningsinstrument av (den påhittade) modellen ”Breathalizer 2000”, och att tillverkaren uppger att sannolikheten att sållningsinstrumentet missar en rattfyllerist är 1 %, och att sannolikheten att en nykter förare testar positivt är 2 %. Detta låter bra, men du som har lärt dig Bayes formel är skeptisk.
a) Skulle det vara rättssäkert att misstänka en slumpmässigt utvald förare för rattfylleri efter att hen har testat positivt i en ”Breathalizer 2000”?
b) Hur påverkas svaret i a) om tillverkaren lyckas få ner risken att en nykter förare testar positivt till 1 %? 0,5 %? 0,1 %?
c) Skulle det vara rättssäkert att använda ”Breathalizer 2000” i situationer där föraren genom sin körning och sitt beteende har fått en polispatrull att redan misstänka rattfylleri, så att sannolikheten att föraren är rattfull bedöms vara 1/10 (snarare än den genomsnittliga sannolikheten 1/500)?
Låt R beteckna hypotesen att föraren är rattfyllerist, och låt + beteckna observationen att föraren har testat positivt. Bayes formel ger då
\[P(R|+)=\frac{P(+|R)P(R)}{P(+|R)\cdot R(R)+P(+|\lnot R)\cdot P(\lnot R)}\,.\]
Vi bestämmer de olika delarna var för sig:
- \(\small P(R)=1/500\) är den initiala sannolikheten att föraren är rattfull, innan hen genomgår testet.
- \(\small P(\lnot R)=1-1/500=499/500\) är den initiala sannolikheten att föraren är oskyldig.
- \(\small P(+|R)=0{,}99\) är sannolikheten att en full förare testar positivt.
- \(\small P(+|\lnot R)=0{,}02\) är sannolikheten att en oskyldig förare testar positivt.
Vi får därmed att
\[P(R|+)=\frac{0{,}99\cdot \tfrac{1}{500}}{0{,}99\cdot \tfrac{1}{500}+0{,}02\cdot \tfrac{499}{500}}\approx 0{,}090\,,\]
dvs. sannolikheten att föraren är rattfull har å ena sidan ökat kraftigt från den initiala sannolikheten på 1/500, men den är fortfarande mindre än 1/10. Den moraliskt och juridiskt komplexa frågan om det är tillräcklig grund för att utsätta föraren för noggrannare utredningsåtgärder lämnas åt läsaren att fundera på.
\(\small P(+|\lnot R)=0{,}01\) ger \(\small P(R|+)=0{,}17\),
\(\small P(+|\lnot R)=0{,}005\) ger \(\small P(R|+)=0{,}28\),
\(\small P(+|\lnot R)=0{,}001\) ger \(\small P(R|+)=0{,}66\),
vilket är en klar förbättring mot a) ur rättssäkerhetssynpunkt!
\(\small P(+|\lnot R)=0{,}02\) och \(\small P(R)=0{,}1\) ger
\[P(R|+)=\frac{0{,}99\cdot 0{,}1}{0{,}99\cdot 0{,}1+0{,}02\cdot \tfrac{499}{500}}\approx 0{,}83\,,\]
så att använda Breathalizer 2000 i fall där föraren redan har uppträtt suspekt är betydligt mer rättssäkert än att använda den i slumpmässiga trafikkontroller.
Vid en mordutredning hittas blodspår från gärningspersonen på brottsplatsen och mordvapnet. Vid en sökning i en stor databas över DNA-profiler upptäcker polisen att DNA-spåren stämmer relativt väl med Anna, som därför blir misstänkt för brottet. Kriminalteknikerna bedömer att träffen är så pass bra att sannolikheten att den skulle ha uppstått om Anna vore oskyldig är 1/1000.
a) Ett klassiskt misstag är att utifrån ovanstående information dra slutsatsen att sannolikheten för att Anna är skyldig är \(\small 1-\tfrac{1}{1000}=\tfrac{999}{1000}\), dvs. ett väldigt högt tal. Detta är dock helt felaktigt. Försök göra en bättre uppskattning med hjälp av Bayes formel! Ange vilka antaganden du gör.
b) Anta nu att polisen hittar ytterligare bevis: ett fotavtryck som matchar Annas skor hittas på flera ställen på brottsplatsen. Eftersom Annas skomodell och skostorlek är ganska vanliga är detta inget särskilt starkt bevis, utan polisen uppskattar sannolikheten för att hitta detta spår om Anna vore oskyldig till 1/500. Anta även att polisen får tag på ett vittne som såg gärningspersonen lämna brottsplatsen springandes. Enligt vittnet ser Anna ”precis ut som gärningspersonen”. Sannolikheten för att vittnet skulle peka ut Anna om Anna vore oskyldig bedöms också vara 1/500.
Uppskatta sannolikheten för att Anna är skyldig givet vitnesmålet, fotavtrycksmatchningen samt DNA-spåret. Diskutera: Är detta tillräckligt för att döma Anna för mordet?
Låt S betecknas hypotesen att Anna är skyldig, och låt E1 beteckna observationen att Annas DNA matchar gärningspersonens DNA. Vi är intresserade av \(\small P(S|E_1)\),
som enligt Bayes formel ges av
\[\small P(S|E_1)=\frac{P(E_|S)P(S)}{P(E_1|S)P(S)+P(E_1|\lnot S)P(\lnot S)}\,.\]
Vi uppskattar de ingående sannolikheterna var för sig:
- \(\small P(S)\) är den initiala sannolikheten för att Anna är skyldig, innan vi upptäckte DNA-matchningen. Att uppskatta denna är antagligen det svåraste i hela uppgiften, eftersom det finns juridiska och filosofiska argument att ta hänsyn till. Ett sätt att se på saken är att domstolen bör vara helt neutral och inte ha några som helst förutfattade meningar innan bevisning har presenterats. Det skulle innebära domstolen initialat utgår från att \(\small P(S)=0{,}5\). Detta motsäger dock principen om att alla ska betraktas som oskyldiga till motsatsen har bevisats. Följer vi den principen borde vi i stället sätta \(\small P(S)=0\). Men det är inte rimligt det heller! Det skulle innebära att vi initialt är helt säkra på att Anna är oskyldig, och då säger Bayes formel (kontrollräkna gärna!) att den uppdaterade sannolikheten blir 0, oavsett hur starka bevis som förs fram. Som kompromiss väljer vi därför att betrakta alla ~10 miljoner invånare i Sverige som lika misstänka, vilket motsvarar att sätta \(\small P(S)=\tfrac{1}{10\,000\,000}\).
- \(\small P(\lnot S)=1-P(S)=\tfrac{9\,999\,999}{10\,000\,000}\) är den initiala sannolikheten för att Anna är oskyldig.
- \(\small P(E_1|S)=1\) är sannolikheten för att Annas DNA skulle matcha gärningspersonens, om Anna vore gärningspersonen. Denna sannolikhet borde rimligtvis vara 1.
- \(\small P(E_1|\lnot S)=\tfrac{1}{1000}\) är sannolikheten för att Annas DNA skulle matcha gärningspersonens, om Anna vore oskyldig.
Bayes formel ger nu att
\[\small P(S|E_1)=\frac{1\cdot \tfrac{1}{10\,000\,000}}{1\cdot \tfrac{1}{10\,000\,000}+\tfrac{1}{1000}\cdot\tfrac{9\,999\,999}{10\,000\,000}}\approx 0{,}001\,,\]
dvs. sannolikheten att Anna är skyldig, om vi bara tar hänsyn till just det här beviset, är väldigt låg.
Låt E2 beteckna observationen att Annas skor matchar gärningspersonens fotavtryck. Låt E3 beteckna observationen att vittnet pekar ut Anna som gärningspersonen. Vi är intresserade av \(\small P(S|E_1\,\&\, E_2\,\&\, E_3)\). Enligt Bayes formel ges den av
\[\small P(S|E_1\,\&\,E_2\,\&\,E_3)=\frac{P(E_1\,\&\,E_2\,\&\,E_3|S)P(S)}{P(E_1\,\&\,E_2\,\&\,E_3|S)P(S)+P(E_1\,\&\,E_2\,\&\,E_3|\lnot S)P(\lnot S)}\,.\]
Vi bestämmer de ingående sannolikheterna var för sig:
- \(\small P(S)=\tfrac{1}{10\,000\,000}\) är den initiala sannolikheten för att Anna är skyldig, innan polisen hade några bevis.
- \(\small P(\lnot S)=1-P(S)=\tfrac{9\,999\,999}{10\,000\,000}\) är den initiala sannolikheten för att Anna är oskyldig.
- \(\small P(E_1\,\&\,E_2\,\&\,E_3|S)=1\) är sannolikheten för att Annas DNA, fotavtryck och utseende skulle matcha om gärningspersonens, om Anna vore skyldig.
- \(\small P(E_1\,\&\,E_2\,\&\,E_3|\lnot S)=\tfrac{1}{1000}\cdot \tfrac{1}{500}\cdot\tfrac{1}{500}\) är sannolikheten för att Annas DNA, fotavtryck och utseende skulle matcha om gärningspersonens, om Anna vore oskyldig. Eftersom de tre bevisen är oberoende av varandra kan vi multiplicera ihop sannolikheterna för att få den totala sannolikheten.
Bayes formel ger nu att
\[\small P(S|E_1\,\&\,E_2\,\&\,E_3)=\frac{1\cdot \tfrac{1}{10\,000\,000}}{1\cdot \tfrac{1}{10\,000\,000}+\tfrac{1}{1000}\cdot \tfrac{1}{500}\cdot\tfrac{1}{500}\cdot\tfrac{9\,999\,999}{10\,000\,000}}\approx 96\,\%\,.\]
Slutsats: Trots att inget av de tre bevisen ensamt räcker till en uppdaterad sannolikhet på ens 1 %, så ger de tillsammans en uppdaterad sannolikhet på 96 %. Det är en hög siffra, men är det tillräckligt för att döma Anna för mordet? Sannolikheten att hon trots allt är oskyldig är 4 %, dvs. 1/25. Det är knappast helt försumbart. Den moraliskt komplexa frågan om vad som krävs för att något ska vara bevisat bortom allt rimligt tvivel lämnas åt läsaren att fundera på.
Bayes formel används ofta i skräppostfilter för att avgöra hur sannolikt det är att ett visst mejl är spam. Exakt hur detta fungerar är komplicerat (du kan läsa mer på Wikipedia). Vi visar här ett väldigt grundläggande exempel.
Anta att du har lagt märke till att ordet ”chance” (som i ”you have the chance to win 1 million dollar!”) ofta förekommer i skräppostmeddelanden. En snabb genomgång av det senaste årets mejl ger att du totalt fick 2431 e-postmeddelanden, varav 230 var skräppost och 2201 inte var skräppost. Av skräppostmeddelandena innehöll 25 stycken ordet ”chance”, och av de meddelanden som inte var spam innehöll 21 stycken ordet ”chance”.
Anta att du får ett mejl där ordet ”chance” förekommer. Använd Bayes formel för att göra en uppskattning av sannolikheten för att mejlet är spam.
Låt S beteckna hypotesen att meddelandet är spam, och låt C beteckna observationen att det innehåller ordet ”chance”. Vi är intresserade av \(\small P(S|C)\), som enligt Bayes formel ges av
\[P(S|C)=\frac{P(C|S)P(S)}{P(C|S)P(S)+P(C|\lnot S)P(\lnot S)}\,.\]
Vi uppskattar, med hjälp av statistiken i uppgiftstexten, de ingående sannolikheterna var för sig:
- \(\small P(S)=\tfrac{230}{2431}\approx 9\,\%\) är den initiala sannolikheten för att meddelandet är spam, innan vi har tagit hänsyn till dess innehåll.
- \(\small P(\lnot S)=\tfrac{2201}{2431}\approx 91\,\%\) är sannolikheten för att meddelandet inte är spam.
- \(\small P(C|S)=\tfrac{25}{230}\approx 83\,\%\) är sannolikheten att meddelandet skulle innehålla ordet ”chance” om det vore spam.
- \(\small P(C|\lnot S)=\tfrac{21}{2201}\approx 1\,\%\) är sannolikheten att ett meddelande skulle innehålla ordet ”chance” om det inte vore spam.
Sätter vi in detta i formeln (utan att avrunda i onödan!), så får vi
\[P(S|C)=\frac{\tfrac{25}{230}\cdot \tfrac{230}{2431}}{\tfrac{25}{230}\cdot \tfrac{230}{2431}+\tfrac{21}{2201}\cdot\tfrac{2201}{2431}}\approx 54\,\%\,.\]
Från detta drar vi slutsatsen att enbart förekomsten av ordet ”chance” inte är en tillräcklig anledning att automatiskt slänga ett inkommande mejl i spam-mappen. Men genom att upprepa den här proceduren med fler suspekta ord (eller hela meningar) kan vi steg för steg uppdatera sannolikheten för att mejlet är spam, och till slut få en ganska bra uppskattning.
Det är första baddagen på året, och du letar efter dina badkläder. Du är inledningsvis ganska säker (låt oss säga 80 %) på att de finns i din byrå. Eftersom byrån har åtta stycken lådor, och du (ostrukturerad som du är) inte har någon aning om i vilken låda kan ha lagt dem, är sannolikheten att badkläderna ligger i en godtyckligt vald låda (80 %)/8=10 %. Anta att du väljer att helt enkelt leta igenom lådorna i tur och ordning.
Tyvärr visar det sig att du inte hittar badkläderna i första lådan, andra lådan, tredje lådan… Sakta men säkert börjar du tvivla: kanske ligger badkläderna inte alls i byrån trots allt? Den här uppgiften går ut på att illustrera detta växande tvivel i en graf.
a) Hur stor är den uppdaterade sannolikheten för att hitta badkläderna i byrån, efter att det har visat sig att de inte fanns i den första byrålådan?
b) Anta nu att du har letat igenom n stycken lådor utan att hitta badkläderna. Hur stor är den uppdaterade sannolikheten att badkläderna finns i byrån? Plotta resultatet för \(\small n=0,1,\ldots,8\).
c) Upprepa uppgift b), men i ett scenario där du är mer självsäker och bedömer att sannolikheten för att hitta badkläderna i byrån är 99 % innan du börjar leta.
Låt H beteckna hypotesen att badkläderna finns i byrån, och låt E1 beteckna observationen att badkläderna inte fanns i den första lådan du sökte igenom.
Det vi är intresserade av är \(\small P(H|E_1)\), som enligt Bayes formel ges av
\[P(H|E_1)={\small\frac{P(E_1|A)\cdot P(H)}{P(E_1|A)\cdot P(H)+P(E_1|\lnot H)\cdot P(\lnot H)}}\,.\]
Vi bestämmer de olika delarna av formeln var för sig:
- \(\small P(H)\) är den initiala sannolikheten för att badkläderna finns i byrån, innan du har börjat leta. Enligt uppgiftstexten är \(\small P(H)=0{,}8\).
- \(\small P(\lnot H)\) är den initiala sannolikheten att badkläderna inte finns i byrån, dvs. \(\small P(\lnot H)=1-0{,}8=0{,}2\).
- \(\small P(E_1|A)\) är sannolikheten att inte hitta badkläderna i den första lådan, förutsatt att badkläderna verkligen finns i byrån. Detta är samma sak som sannolikheten för att badkläderna finns i någon av de 7 kvarvarande lådorna du inte har letat igenom, återigen förutsatt att badkläderna finns i byrån. Det betyder att \(\small P(E_1|A)=7/8\).
- \(\small P(E_1|\lnot H)\) är sannolikheten att inte hitta badkläderna i den första lådan om badkläderna inte finns i byrån. En stunds eftertanke ger att \(\small P(E_1|\lnot H)=1\).
Vi har nu att
\[P(H|E_1)=\frac{\tfrac{7}{8}\cdot 0{,}8}{\tfrac{7}{8}\cdot 0{,}8+1\cdot 0{,}2}\approx 0{,}77\,.\]
Låt H beteckna hypotesen att badkläderna finns i byrån, och låt En beteckna observationen att badkläderna inte fanns i de n första lådorna du sökte igenom.
Det vi är intresserade av är \(\small P(H|E_n)\), som enligt Bayes formel ges av
\[P(H|E_n)={\small\frac{P(E_n|A)\cdot P(H)}{P(E_n|A)\cdot P(H)+P(E_n|\lnot H)\cdot P(\lnot H)}}\,.\]
Vi bestämmer de olika delarna av formeln var för sig:
- \(\small P(H)\) är den initiala sannolikheten för att badkläderna finns i byrån, innan du har börjat leta. Enligt uppgiftstexten är \(\small P(H)=0{,}8\).
- \(\small P(\lnot H)\) är den initiala sannolikheten att badkläderna inte finns i byrån, dvs. \(\small P(\lnot H)=1-0{,}8=0{,}2\).
- \(\small P(E_n|A)\) är sannolikheten att inte hitta badkläderna i de n första lådorna förutsatt att badkläderna verkligen finns i byrån. Detta är samma sak som sannolikheten för att badkläderna finns i någon av de \(\small 8-n\) lådorna du inte har letat igenom, igen förutsatt att badkläderna finns i byrån. Det betyder att \(\small P(E_n|A)=\tfrac{8-n}{8}\).
- \(\small P(E_n|\lnot H)\) är sannolikheten att inte hitta badkläderna i de n första lådorna om badkläderna inte finns i byrån. En stunds funderande ger att \(\small P(E_n|\lnot H)=1\).
Vi har nu att
\[P(H|E_n)=\frac{\tfrac{8-n}{8}\cdot 0{,}8}{\tfrac{8-n}{8}\cdot 0{,}8+1\cdot 0{,}2}\,.\]
Eftersom vi ska plotta resultatet avstår vi från att förenkla detta uttryck. (Att behålla uttrycket på den här formen har fördelen att vi enkelt kan identifiera var de olika delarna kommer ifrån, och att risken för avskrivningsfel därmed minskar.)
Plottar vi detta i ett kalkylbladprogram eller WolframAlpha erhålls följande:
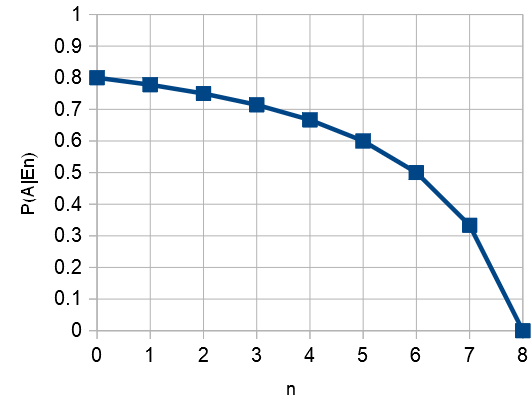
Notera att resultatet för \(\small n=0\) och \(\small n=8\) är vad de borde vara, och att resultatet för \(\small n=1\) stämmer med resultatet i a).
Vi får nu följande plot:
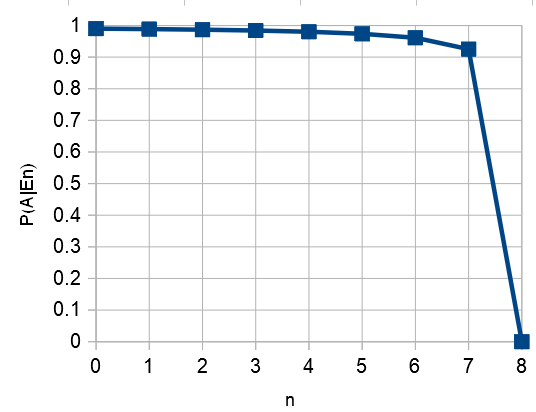
Notera nu att hoppet om att hitta badkläderna i byrån håller sig konstant högt ända tills den sista lådan har genomsökts. Efter detta gör den blå kurvan en störtdykning ner till 0. Detta är rimligt, eftersom du ju var nästan helt övertygad (99 %) om att badkläderna fanns i byrån innan du började leta, så det är verkligen med stor förvåning som du konstaterar att du hade fel efter att ha letat igenom alla åtta lådorna.
Ett kalkylblad för beräkningar och plottar som de i artikeln kan laddas ner här.